
In a recent Google Hangout, John Mueller confirmed that they index PDF files in the Google Search Results just like they would any other webpage. John Muller also gave insight into why such a PDF file may not be indexed, despite this.
In the Google Hangout, the following question was asked at time 18:48:
Question: I can’t seem to get a lot of my pdfs indexed on my product pages. Should I just add the content on my product tab as well, so it’s in both places? Will that cause duplication issues and any idea why they won’t index?
John Mueller: In general we index PDF files like we would like other normal pages on a website. What probably will happen with PDFs is that we don’t much refresh them as quickly as normal HTML pages because we assume that the PDF files stay stable. But that doesn’t sound like your problem. With regards to the indexing of PDF files, if we see links to those pages, we will try to index those pages to get them into the search results.
John Mueller: So if we are not able to index those pages then either we are having trouble finding the links to those PDF files which might be because they are hard to find on the website or maybe they are not in static HTML or they have a nofollow link or something like that. Or it might just be that we are saying we have enough content indexed from your website already.
We are not ready yet to add a significant batch of more content. So we can’t guarantee that we index all content on a website which means that for some websites, in some situations, we might have a cutoff and say we have indexed a lot of content from this website already.
We’ll keep crawling more content from this website, and if we find something really compelling, we will include that in the index as well. Maybe these PDFs are content we have looked at or content we haven’t had time to look at from the website.
John Mueller: If there is important content in those PDFs that you do need to have indexed then it might be worth including on the product page directly. That way people don’t have to download the PDF actually to see that content. So if it is important, maybe put it directly on the page. If it is more auxiliary content, like reference material that people might want to look at but doesn’t need to rank separately then maybe it is fine just linking from your product pages.
You can view the relevant part of the discussion below:
PDF File Indexing FAQ
This is not the first time the issue of indexing PDF files has come up. In a Webmaster Central Blog Post back in September 2011, Google’s Gary Illyes answered some questions about PDF indexing, which we will summarize below:
Can Google Index PDF Files?
In general, yes, Google does crawl PDFs unless they are password protected or encrypted. If the text is embedded as images, Google may process those images to extract the text. The general rule is that if you can copy \ paste text from a PDF document, Google should be able to search pdf content and index the content.
What happens with the images in PDF Files?
Images within PDF files are not indexed (as at 2011).
How are links treated in PDF Files?
Links are treated the same as links within Web pages. They pass PageRank and other indexing signals and will be followed when crawled. It is not possible to “nofollow” links in a PDF file.
How can I prevent my PDF files from appearing in search results; or if they already do, how can I remove them?
You should add an “X-Robots-Tag: noindex” in the HTTP Header used to serve the file. If they are already indexed, then implemented the header will cause them to drop out over time. Alternatively, you can use the URL Removal Tool.
Can PDF files rank highly in the search results?
PDF files can rank similar to Web pages.
Is it considered duplicate content if I have a copy of my pages in both HTML and PDF?
Yes. If you need to serve both copies, then you should canonicalize one version to the other.
How can I influence the title shown in search results for my PDF document?
Google uses the title metadata within the file and the anchor text of links pointing to the PDF file. Google recommends setting both.
How to search for PDF files in Google
If you wish to search for PDF files in Google, you can use the “filetype:” operator.
To search PDF files for the search term “SEO PDF” type the following:
filetype:pdf SEO PDF- Then hit “Google Search.”

You can see a screenshot of the results in the screenshot.
PDF Files can even show in Featured Snippets
On January 17, 2019, Kevin Indig reported on Twitter that Google is now pulling featured Snippets from PDF files.
I tried the example given, and it was still working as of January 26th. You can see the screenshot below:
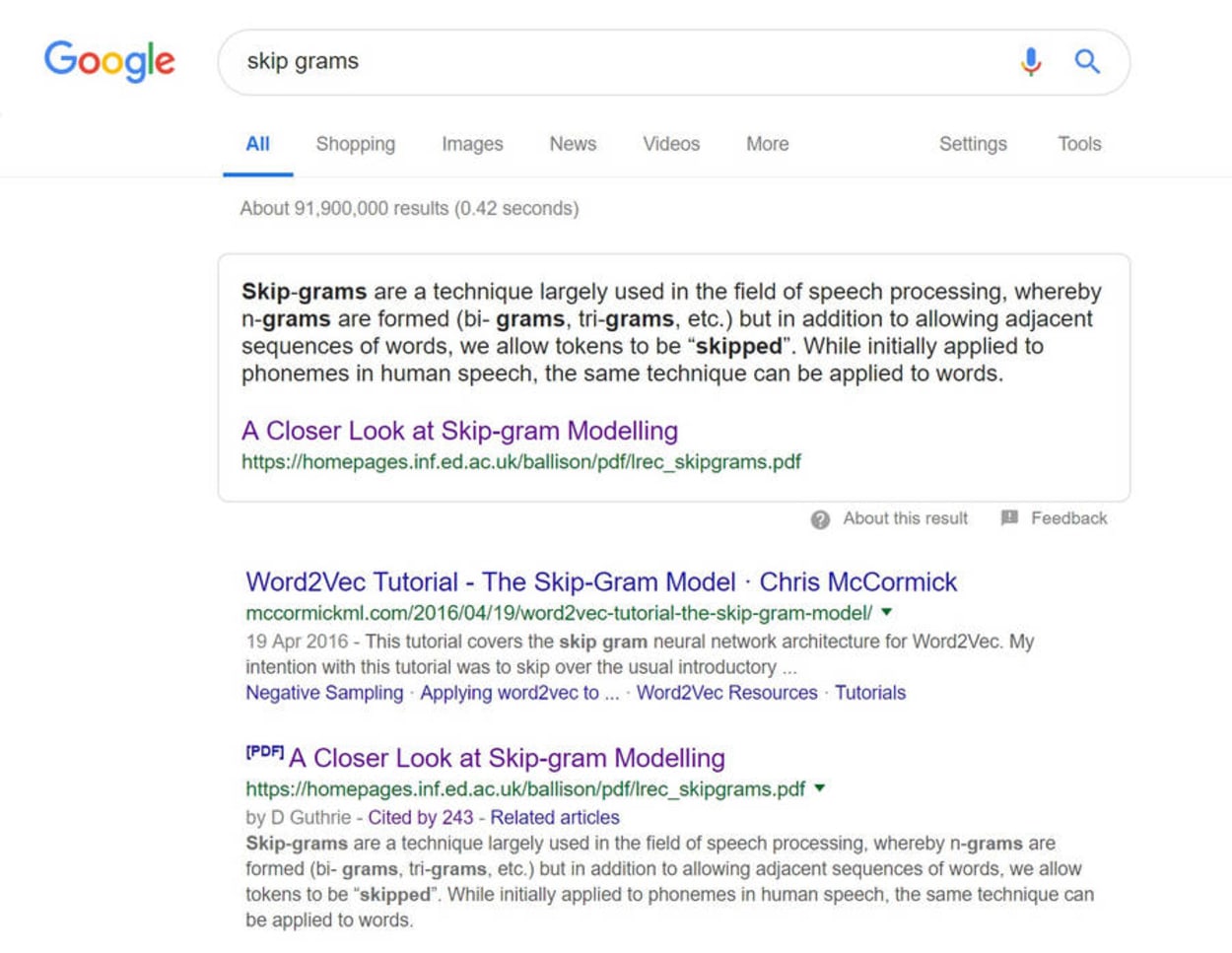
You can bet your life that many SEO specialists will now be optimizing their PDF for the Search Engines.
Other file types Indexable by Google
PDFs are just one of a large number of file types that can be indexed by Google.
Google can index the content of most types of pages and files, including Adobe Flash, Microsoft documents such as Excel and Docs, Rich Text Format, OpenOffice documents, PowerPoint, and various programming languages.
You can find a full list of indexable files here.