
Google’s John Mueller was asked in a recent Webmaster Central office-hours hangout whether they have any plans to bring back the 404 sources report in the old Webmaster Tools.
Mueller confirmed that there are some discussions internally about the crawl error report functionality, but that he does not “know what the current status is.”
He said he would “poke at it again.”
You can view the complete discussion below:
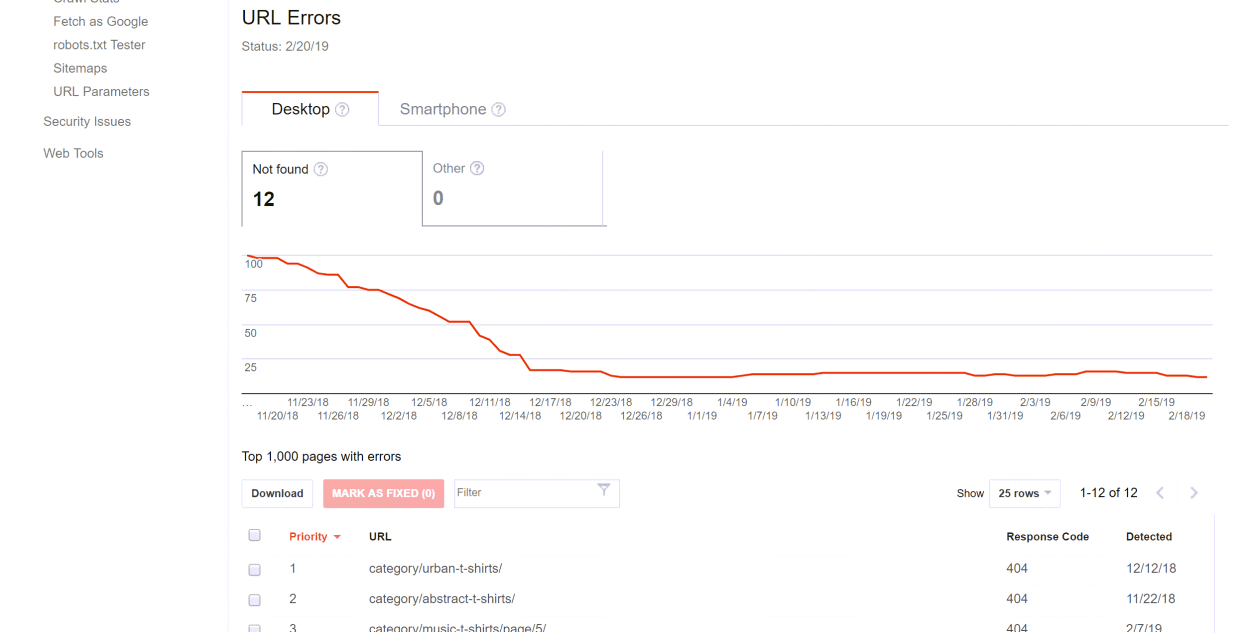
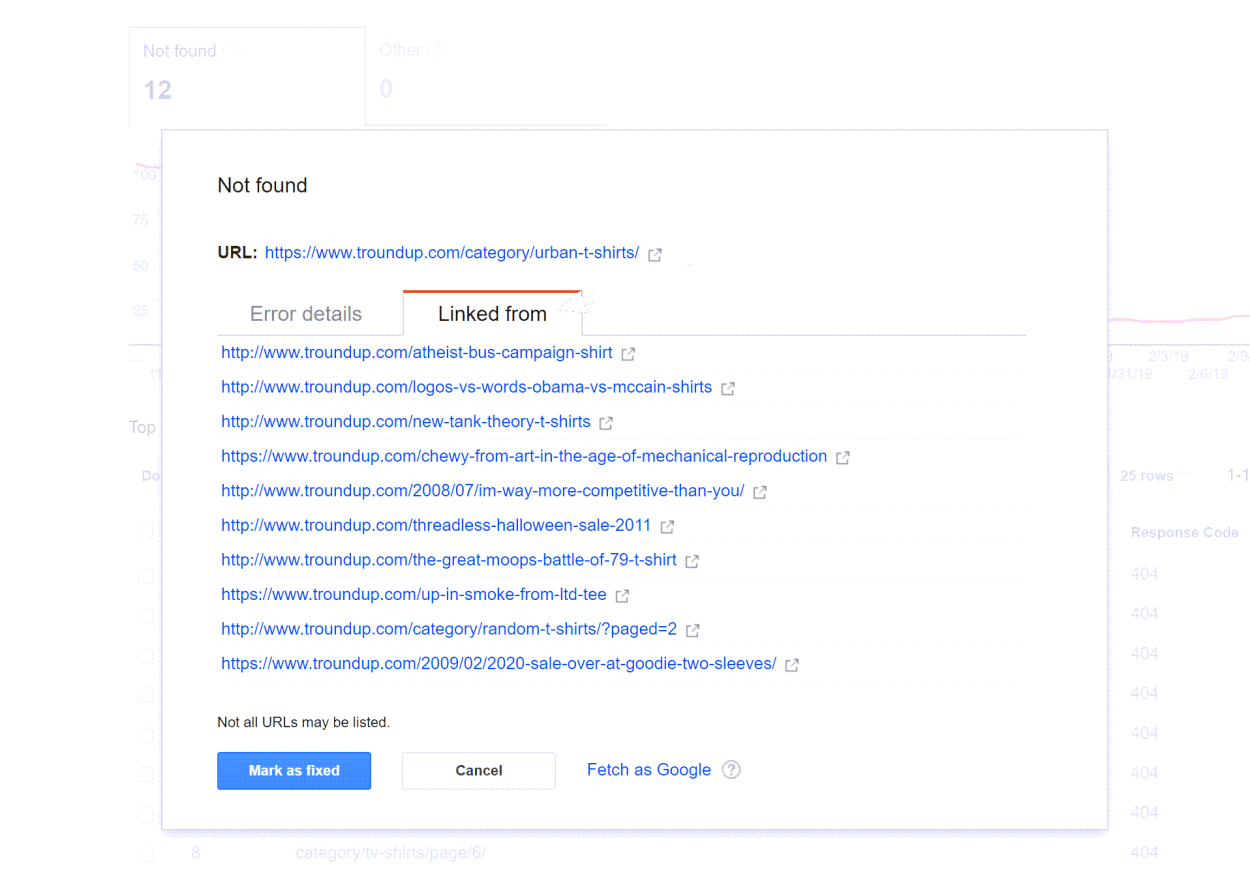
The Crawl Error sources report was introduced in October 2008 and allowed webmasters to identify the sources of URLs causing errors, such as 404 “Not found” errors.
You can view a couple of screenshots of the old functionality below:
In January 2018, Google introduced the new Search Console to replace the old Webmaster Tools.
Features were gradually moved over, often changing in the process.
Google published a migration guide, setting out the equivalent functionality in the new Search Console.
In it, Google points you to the Index Coverage report, and the URL Inspection tool, but this falls short in several ways. According to the migration guide:
- Crawl errors are shown at the site level in the Index Coverage report, and URL level in the Inspection tool.
- The old report showed three months of data, while the new report covers just the last month.
- 404’s are only considered an error if you specifically asked Google to crawl it, such as via a sitemap.
According to Google:
These new behaviors help you focus on issues that affect your site in the Google index, rather than simply reporting a laundry list of all errors that Googlebot ever encountered on your site.
I can see that Google is trying to provide more useful actionable data for webmasters, but I wonder if they have missed something vital here.
Being able to add redirects from 404 pages to other useful content, especially where orphaned links are involved, for example, surely is a high priority issue.