
HTTP/2 is one of the most significant changes to how the web works since HTTP v1.1 was released in June 1999. The new HTTP/2 protocol makes web pages load significantly faster (14 percent faster if you believe our benchmarks) on desktop and mobile devices.
Tim Berners-Lee created HTTP to allow communication between a server and a client. It is this communication that forms the basis of the Internet.
I’ll talk about what HTTP is shortly, but first, it is helpful to run through a brief history of HTTP:
HTTP 0.9 - Time Berners-Lee released the first documented version of HTTP in 1991.
It consisted of a single line containing a GET method and the path of the requested document. The response was just as simple, returning a single hypertext document without headers or any other metadata.
HTTP 1.0 - Version 1.0 received official recognition in 1996 and coincided with the rapid evolution of the HTML specification and the “web browser.”
The main addition was “request headers” and “response headers.” Also, the new response headers allowed multiple file types, such as HTML, plain text, images, and more.
HTTP 1.1 - Version 1.1 was released in 1997 and became the Internet Standard. This version added many performance enhancements, including keepalive connections, caching mechanisms, request pipelining, transfer encodings, and byte-range requests.
This new version was better and removed many of the ambiguities found in HTTP/1.0.
HTTP 2.0 - Released in February 2015 by the Internet Engineering Task Force (IETF) focussed on improving HTTP performance. This article focuses on the significant changes of this version in more detail.
HTTP 3 - The new HTTP/3, based on the QUIC protocol, is anticipated to be released in late 2019. I discuss HTTP/3 briefly at the end of this article.
What is HTTP?
HTTP stands for Hypertext Transfer Protocol. It is the foundation of the World Wide Web and is used by browsers to load web pages.
A typical example is when your browser sends an HTTP request to a web server after entering an URL. The HTTP command then provides an HTTP response to the web server with the webpage’s contents.
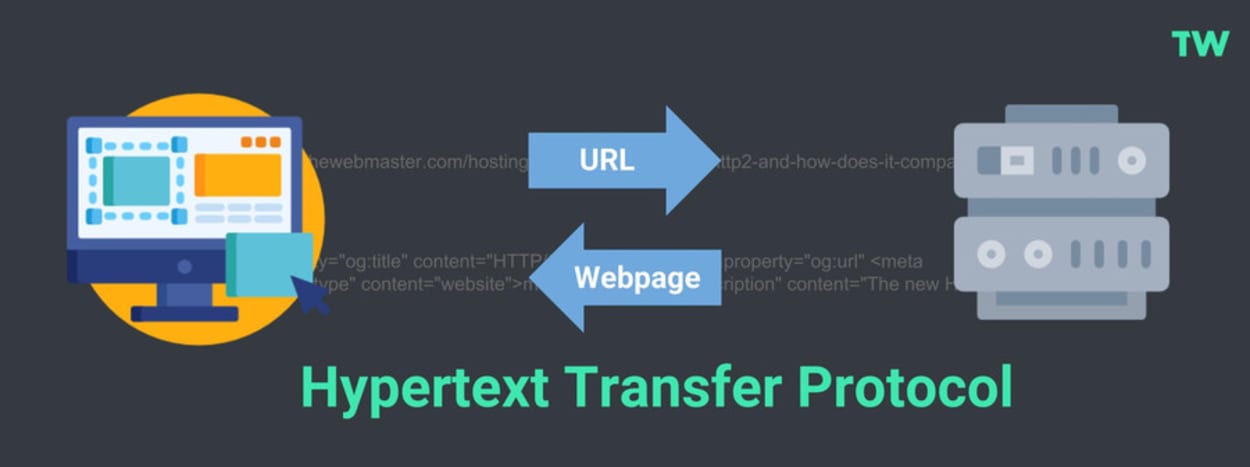
The above example over-simplifies it a little. Let’s look at HTTP requests and HTTP responses in a little more detail:
HTTP Request
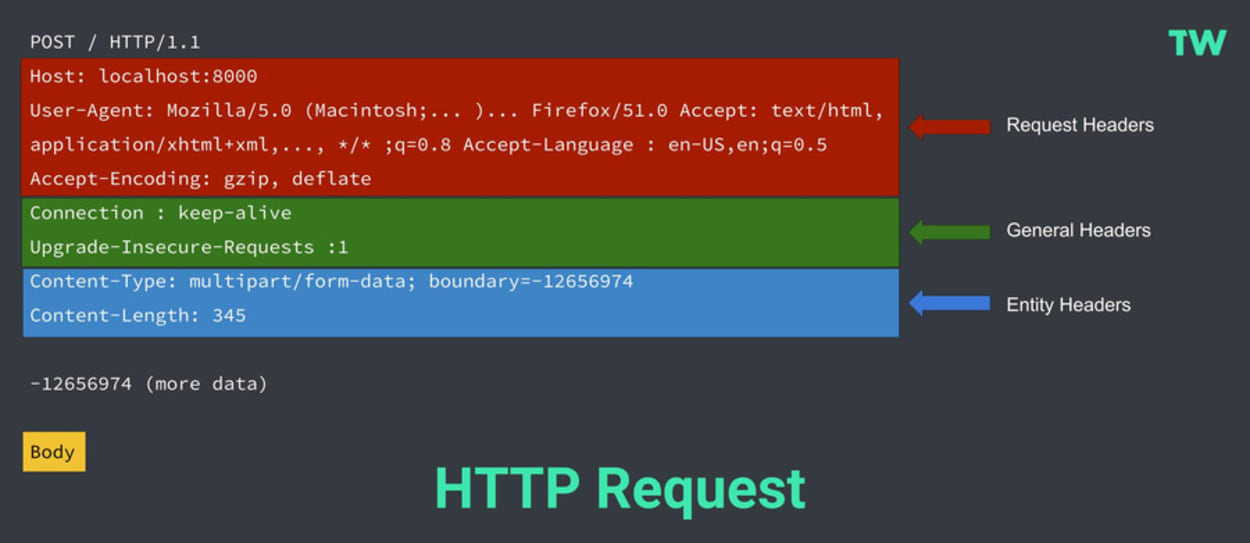
HTTP requests typically comprise the following:
- Start-line - This describes the HTTP Method (such as Get, Put, or Post), the request target (such as an URL or Port), and the HTTP version (such as HTTP/1.1). This start-line is always a single line.
- Request Headers - An optional set of HTTP headers specifying the request. There are multiple different types of headers:
- Request Headers - Includes User-Agent, Accept-Type, Accept-Language.
- General Headers - Includes Connection.
- Entity Headers - Includes Content-Type or Content-Length.
- Blank Line - This confirms that all the request meta-data has been sent.
- Body (Optional) - This contains all the data associated with the request. There are typically two categories:
- A body consisting of one single file, defined by the Content-Type and Content-Length Entity Headers.
- A multipart body. One example could be a request containing information in an HTML form.
HTTP Response

HTTP responses typically comprise the following:
- Start-line - This usually includes the HTTP protocol version (HTTP/1.1), a status code (such as 200 or 404), and a textual description of the status code (such as “ok”).
- Response Headers - An optional set of HTTP headers specifying the request. There are multiple different types of headers:
- Response Headers - such as Vary and Accept-Ranges, provide more information about the server.
- General Headers - such as Via, apply to the whole message.
- Entity Headers - such as Content-Length, or Last-Modified, apply to the response body.
- Body - This contains all the data associated with the request. There are typically two categories:
- A body consisting of one single file, defined by the Content-Type and Content-Length Entity Headers.
- A body consisting of one single resource of unknown length encoded by chunks (Transfer-Encoding set to Chunked).
- A multipart body, with each part containing different information. These are not common.
What is HTTP/2?
HTTP/2 is the next version of HTTP and is based on Google’s SPDY Protocol (originally designed to speed up the serving of web pages). It was released in 2015 by the Internet Engineering Task Force (IETF).
It is important to note that HTTP/2 is not a replacement for HTTP. It is merely an extension, with all the core concepts such as HTTP methods, Status Codes, URIs, and Header Fields remaining the same.
The key differences HTTP/2 has to HTTP/1.x are as follows:
- It is binary instead of textual
- It is fully multiplexed, instead of ordered and blocking
- It can use one connection for parallelism
- It uses header compression to reduce overhead
- It allows Server Pushing to add responses proactively into the Browser cache.
I’ll look at each of these in turn.
Binary Protocol
Binary protocol is a result of one of the core enhancements to HTTP/2. The new binary framing layer relates to how HTTP messages are transmitted between the client (web browser) and server.
The binary framing layer introduced a new encoding mechanism between the socket interface and higher HTTP API used by web applications, such as your browser.
A binary protocol must be used for this new, improved encoding mechanism to work.
Textual vs. Binary
HTTP1.x uses text-based commands to complete HTTP requests. If you were to view one of these requests, they would be perfectly readable (to a system admin, at least).
HTTP2, on the other hand, uses binary commands (1s and 0s) to complete HTTP requests. It needs to be converted back from binary to read the request.
This conversion to Binary takes place in the Binary Framing Layer, so only binary commands are transmitted over the network.

The Framing Layer
I’ve set out earlier two diagrams showing an HTTP/1 request and response. It is helpful to look at an equivalent diagram in the context of the framing layer to conceptualize the difference for HTTP/2.
HTTP/2 introduces an extra step. It divides HTTP/1.x messages into frames embedded in a stream.
With frames, the Data and header frames are separated. Not only does this allow compression, but it also allows multiplexing, making the underlying TCP connections more efficient. I discuss Streams and Multiplexing in the next section.
For now, it is helpful to have the concept of framing in your mind.
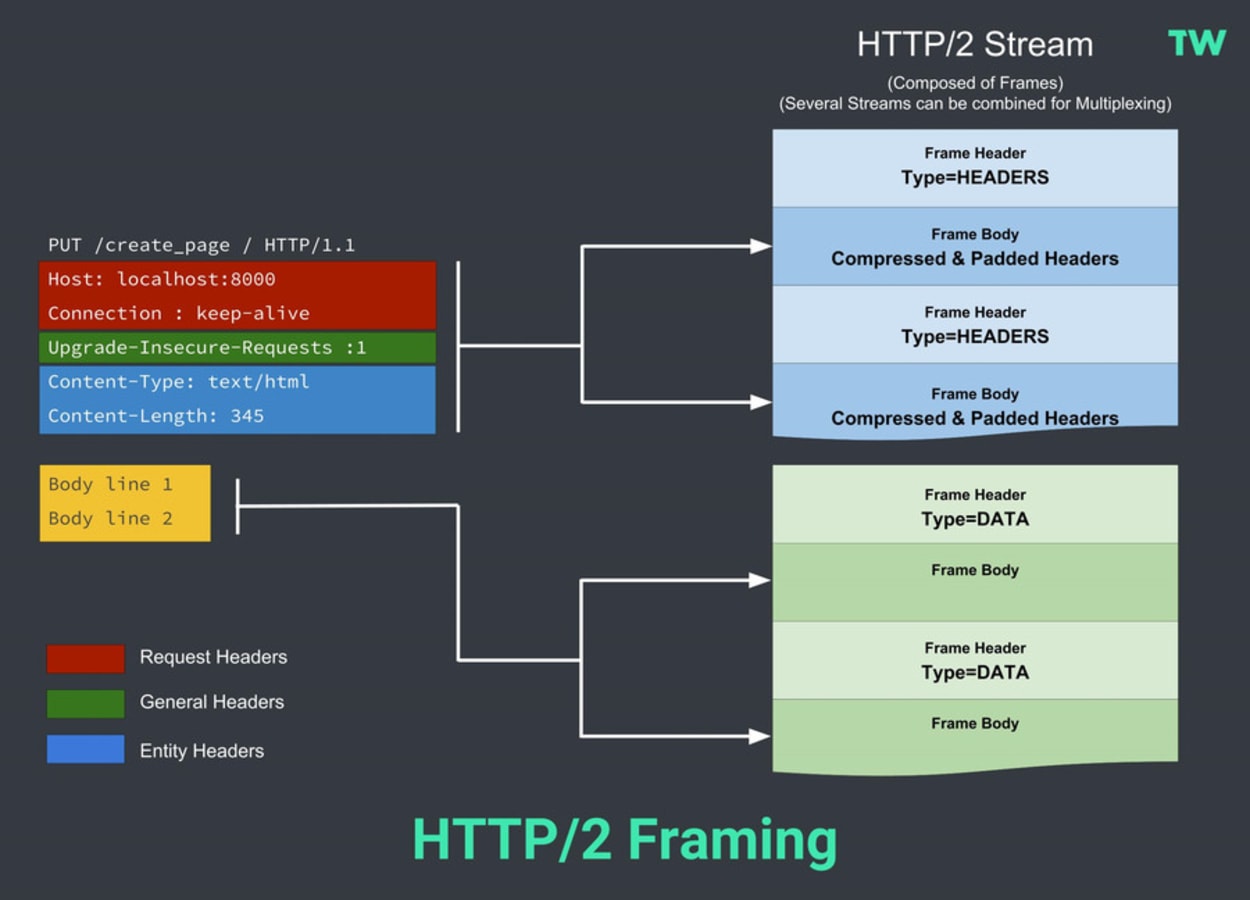
Benefits:
- Enhanced encoding mechanism between the socket interface and HTTP API.
- Binary protocols are more efficient to parse
- They are more compact and more efficient over the network.
- Less error-prone than HTTP/1, as HTTP/1 has many “helpers” to deal with whitespace, capitalization, line endings, etc. The more complexity, the more chance of errors.
- More secure, as security concerns associated with textual attacks, such as splitting, are no longer relevant.
Multiplexing and Concurrency
Modern websites require the web browser to make many requests to render a web page. HTTP/1.0 allowed just one request to be made at a time. HTTP/1.1 allowed multiple requests, but the number of requests was limited to around 6 or 8, depending on the browser.
The number of simultaneous requests by browser:
| Browser | Max Parallel Connections Per Host |
|---|---|
| IE 9 | 6 |
| IE 10 | 8 |
| Firefox 4+ | 6 |
| Chrome 4+ | 6 |
| Safari | 4 |
Many modern websites often require over 100 connections, which when you can only open 6 or 8 connections at a time can cause a website to load more slowly.
Domain Sharding
With HTTP/1.x, if a user wanted to make multiple parallel requests to improve performance, they would need to use a technique such as Domain Sharding.
This is where a user would use a subdomain (or multiple subdomains) for assets such as images, CSS files, and JavaScript files so that they could make two or three times the number of connections to speed up the download of files.
Head-of-line Blocking
This is further exacerbated by a problem called “head-of-line blocking.” This is where a new request can only be made once the results of the first request must have been received.
The new binary framing layer (which I discussed previously) removes these limitations.
It allows full request and response multiplexing by enabling the client and server to break down an HTTP message into independent frames, interleave them, and then reassemble them on the other end. Furthermore, it only uses a single TCP connection to do all this.
Benefits
- Interleave multiple requests in parallel without blocking any one.
- Interleave multiple responses in parallel without blocking any one.
- Use a single TCP connection to deliver multiple requests and responses in parallel.
- Remove unnecessary HTTP/1.x workarounds such as Domain Sharding, Image Sprites, etc.
Akamai has developed a simple demonstration, allowing you to see how multiplexing works by loading two images. Each image is split into 379 small tiles, causing 379 separate connections to be made to the server.
While a website is unlikely to have anywhere near this number of requests, it does amplify just how much faster HTTP/2 is when pushed to the limits.
I have carried out some real-world benchmark tests later in this article, which show a much more realistic speed comparison.
You can see a short video of the demonstration below:
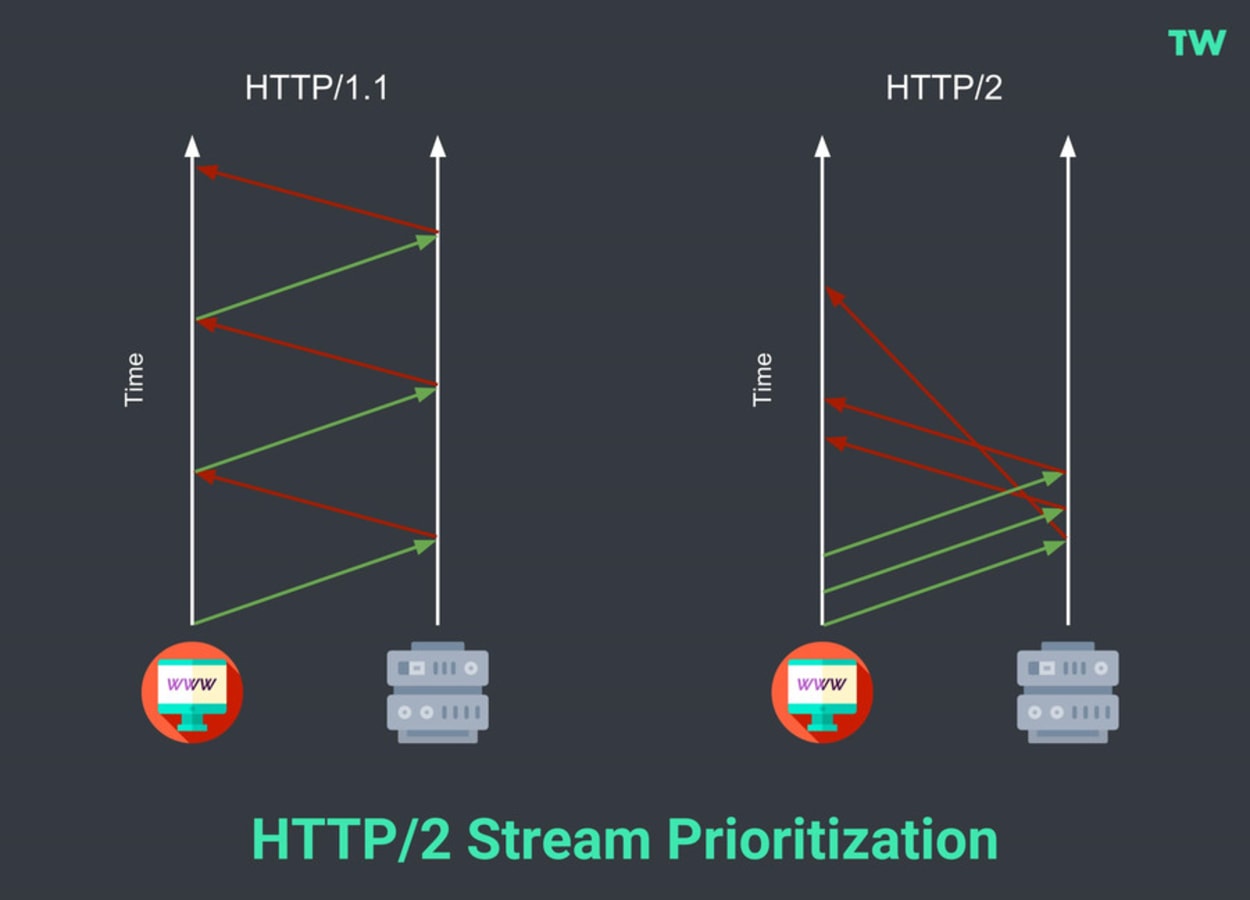
Stream Prioritization
When websites load the assets (HTML, CSS, JavaScript, images) that make up the web page, the order in which they are loaded is important. You can’t have CSS (the styling) load at the end; otherwise, the web page may look deformed for the first few seconds.
Secondly, you can’t have assets that require the jquery library (JavaScript) to load before jquery, as this can even break the functionality of some of the features on the website.
With HTTP/1.1, this was easy, as head-of-line blocking made it simple to load various assets in the correct order. With HTTP/2, however, the response to the browser request may be received back in any order.
The new protocol solves this by allowing the browser to communicate with the server and indicate the priorities for the respective objects \ files.
No changes will be required by web \ app developers as modern web browsers will take care of prioritization and handling of data streams.
The diagram below shows the differences between HTTP/1.1 and HTTP/2 thanks to Stream Prioritization:
Header compression
With HTTP/1.1, a new TCP connection has to be provided for every asset requested, which, if you have a page with over 100 requests, can be time-consuming. The new protocol can send all the headers in a single connection utilizing compression.
Due to a significant “CRIME” attack targeting the use of GZIP Stream Compression, the HTTP/2 developers had to abandon its use. Instead, they created a new header-specific compression scheme called HPACK.
HPACK compresses the individual value of each header before it is transferred to the server. To reconstruct the full header information, it then looks up the encoded information in a list of previously transferred header values.
This creates a significant performance benefit over HTTP/1.
HTTP/2 Server push
Server Push is one of the most hyped but somewhat under-utilized features of HTTP/2.
To fully understand how Server Push works, knowing the differences between a web page loading with and without it is essential.
Page Load without Server Push
A server without Server Push will follow a simple process:
- An HTTP Request is made for the HTML file.
- The Server provides the HTML file in response.
- The HTML document references a CSS file, JavaScript file, and maybe some images. Client requests are then made for those resources, which are then returned by the server.
- Once the resources are returned, the browser renders the page.
You can see this process visualized below:

The problem with this method is that it takes time to discover the assets in the HTML page and more time to retrieve them. This delays the rendering of the web page and increases web page load times.
Page load with Server Push
A server with Server Push will follow an even more straightforward process:
- The HTTP Request is made for the HTML file.
- The Server provides the HTML and CSS files in response.
- The page starts to render straight away.
- Afterward, other less critical assets, such as the JavaScript file and images, can be retrieved.
You can see this process visualized below:
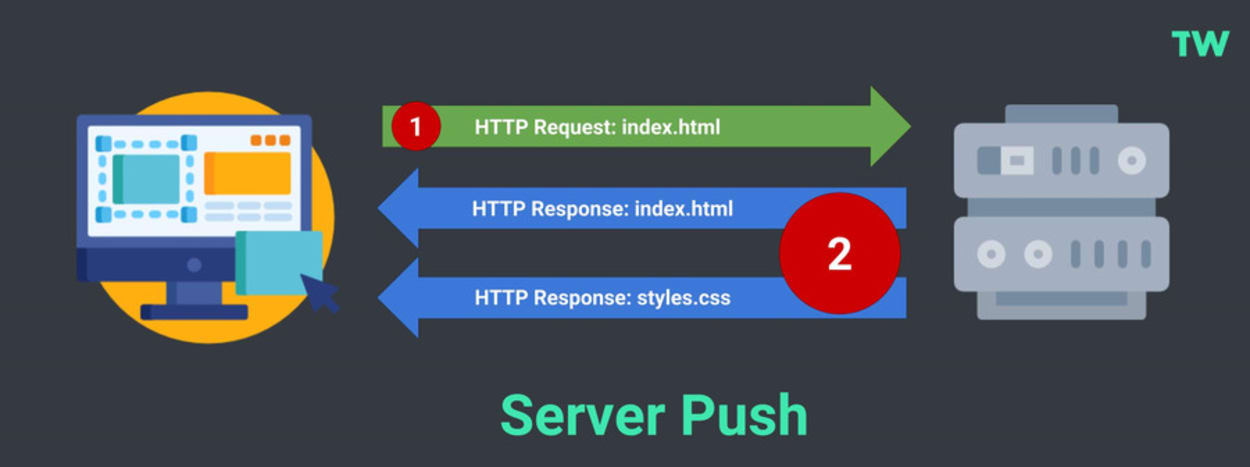
The best practice is not to push all your assets, just the ones that hold up the page from rendering. If you push too many resources at once, it can cause your site to be slower to load, so be careful.
Benefits
- The stylesheet and other critical assets are received at the same time as the HTML page, reducing latency.
- The browser saves the pushed resource into the cache so it can be reused across different pages.
- The server can push the resources within a single TCP connection using multiplexing.
- The server can prioritize push resources, although pushing too many can cause a bandwidth jam.
- The browser can choose whether to use its cached version rather than the pushed resource.
Inlined CSS
A similar effect to server push (at least for your CSS file) can be made by inlining the critical CSS in the header of every HTML page.
This approach is actively promoted by Google’s Lighthouse page speed testing tool, which you can find at web.dev.
The problem with this approach is as follows:
- You will need a developer to create the critical portion of your CSS used to render the visible part of your web page when it is first loaded. It is not as easy as it sounds.
- The CSS will need to be loaded every time, rather than being served from the browser cache on subsequent page loads. This will cause increased latency and a slower site.
- When updating your site’s stylesheet, you will need to clear the cache of every page.
For these reasons, Server Push is a better approach.
HTTP/2 vs. HTTP/1.1 Performance Benchmarks
I’ve seen plenty of HTTP/2 benchmark tests around the web that show how quickly they can load 100 images. I don’t know about you, but I have not seen many websites with that many images.
For my test, I will be basing it on real-world websites.
Methodology
- Websites tested: 7 websites from Alexa’s list of the top 50 Small Business websites. I checked the download size of the page, and the number of requests did not alter between page load and that the website was served via HTTP/2.
- Tested with: Webpagetest.org
- Test Location: Dallas
- Browser: Chrome.
- Page URL: The homepage.
- number of tests: 5 tests were carried out on each URL. The median run was recorded for the Document Complete Time on the first view.
WebPageTest was used for this test because of the ability to fine-tune the speed test settings. In this instance, I was able to test for HTTP/1 by disabling HTTP/2 in Chrome using the –disable-http2 flag.
HTTP/1 vs HTTP/2 Results
Based on a limited set of results, HTTP/2 is faster than HTTP/1.1 by around 14%. I hope to increase the sample size in due course.
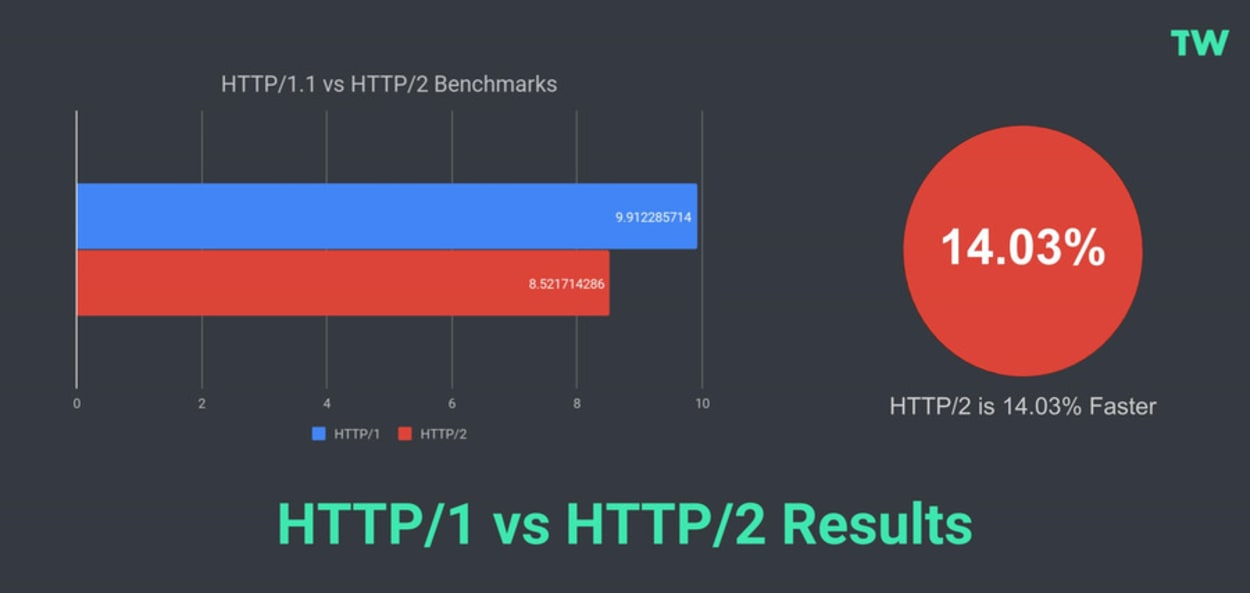
You can view the dataset used here.
HTTP/2 SEO
Page Speed is now a ranking factor for mobile search results. This ranking factor penalizes slow mobile pages rather than giving a boost to faster pages. It is crucial to ensure that your site loads reasonably fast on mobile devices.
Later in 2021, there will also be a new Page Experience ranking factor that will include page performance as part of it (Web Vitals).
Browser HTTP/2 Support (SSL Only)
By the end of 2015, most popular browsers supported HTTP/2. This included Firefox, Microsoft Edge, Internet Explorer 11, and Chrome.
While HTTP/2 does not technically require an SSL certificate to be installed on a website’s server, the leading web browsers (including Firefox and Chrome) said they would only implement HTTP/2 over TLS (HTTPS).
As such, you do need an SSL for your website to take advantage of the new protocol.
Here is the complete list of HTTP/2 capable browsers:
| BROWSER | Compatible | Version Supported From |
|---|---|---|
| IE 11 | ✔️ | 11 (only on Windows 10) |
| Edge | ✔️ | 36 |
| Firefox | ✔️ | 36 |
| Chrome | ✔️ | 41 |
| Safari | ✔️ | 9 (9-10.1 required OSX 10.11+) |
| Opera | ✔️ | 28 |
| Safari for iOS | ✔️ | 9 |
| Opera Mini | ❌ | |
| Opera for Android | ✔️ | 46 |
| Chrome for Android | ✔️ | 71 |
| Firefox for Android | ✔️ | 64 |
| IE Mobile | ❌ |
Web Server HTTP/2 Support
All the main web servers support HTTP/2:
- Apache - As of version 2.4.17 (August 2017), Apache offers native support via the module
mod_http2. Before this version, support was available viamod_h2, but this required manual patches to work. - NGINX - HTTP/2 has been supported since version 1.9.5, released on September 22, 2015, using the
ngx_http_v2_module. HTTP/2 Server push has been supported since version 1.13.9, released on February 20, 2018. - Microsoft-IIS - Windows Server 2016 has offered full support since its release on October 12, 2016.
- LiteSpeed - LiteSpeed Web Server has offered support since version 5, released on April 17, 2015.
According to W3Techs, as of February 1, 2019, 85.3% of all web servers used for websites use either Apache or Nginx.
Microsoft comes third at 8.9%, and LiteSpeed fourth at 3.9%. Other web servers make up the remainder, with 1.9%.
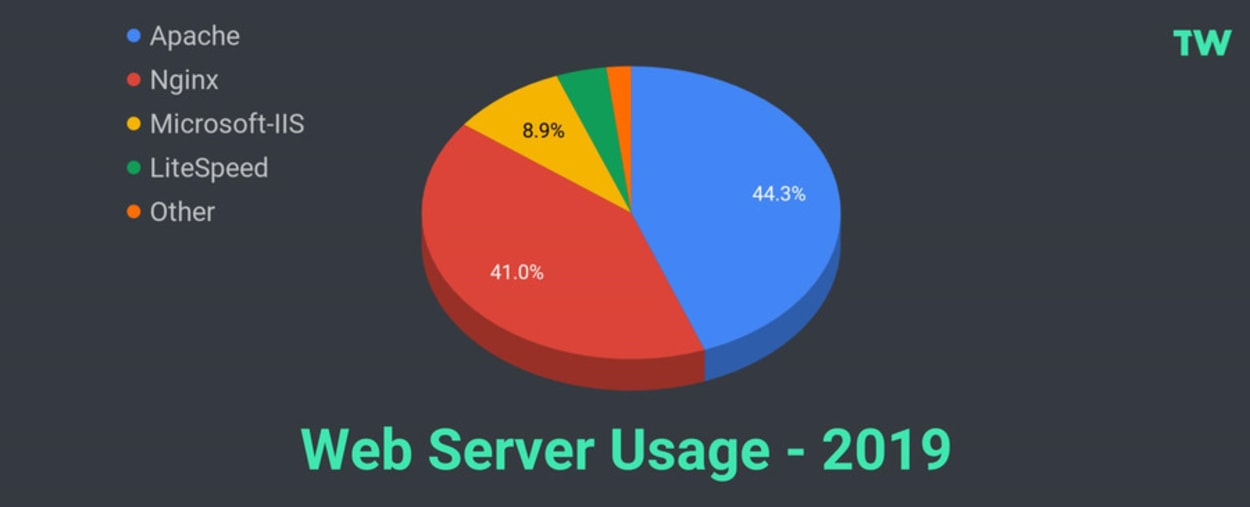
As you can see, most web servers now support HTTP/2.
Most reputable web hosting providers, including my list of top recommended shared hosting providers (SiteGround, A2 Hosting, and TMD Hosting), now offer free SSL and HTTP/2 out the box.
There is no excuse not to be using HTTP/2.
The Future with HTTP/3
HTTP/3 is an evolution of the QUIC (Quick UDP Internet Connections) protocol from Google, first suggested by Mark Nottingham in October 2018. HTTP/3 is due to be released in 2019 (hopefully).
QUIC is similar to TCP+TLS+HTTP2 but is implemented on top of UDP. UDP stands for User Datagram Protocol. UDP is essentially TCP without all the error checking.
This has many benefits:
- UDP packets are received by the recipient more quickly.
- The sender will not have to wait to ensure the packet has been received.
Because no error checks are made, when the recipient misses packets, they cannot be requested again. As a result, UDP is used when speed is more important than the occasional lost packet, such as live broadcasts or online gaming.
Key features of QUIC:
- Dramatically reduced connection establishment time
- Improved congestion control
- Multiplexing without head-of-line blocking
- Forward error correction
- Connection migration
You can read more about QUIC at the Chromium Projects and HTTP/3 in this article from CloudFlare.